Domain-Driven Design: The Key to Modular Solutions
Domain-Driven Design (DDD) in software engineering helps to build modular solutions and has been known for many years. Unfortunately, many systems do not this approaches.
Many software services rely on a technical architecture, such as the classical three-tier architecture. This architectural style consists of services, entities, and data repositories (or data access layers). However, the business architecture (or domain architecture) is often missing or not considered. It seems that many software engineers are not aware of the importance of building modularized solutions.
One Example
Let’s examine a simple order use case: when a customer places an order, the OrderService stores the order. The OrderEntity contains many articles as OrderLines, and this entity is associated with the CustomerEntity.
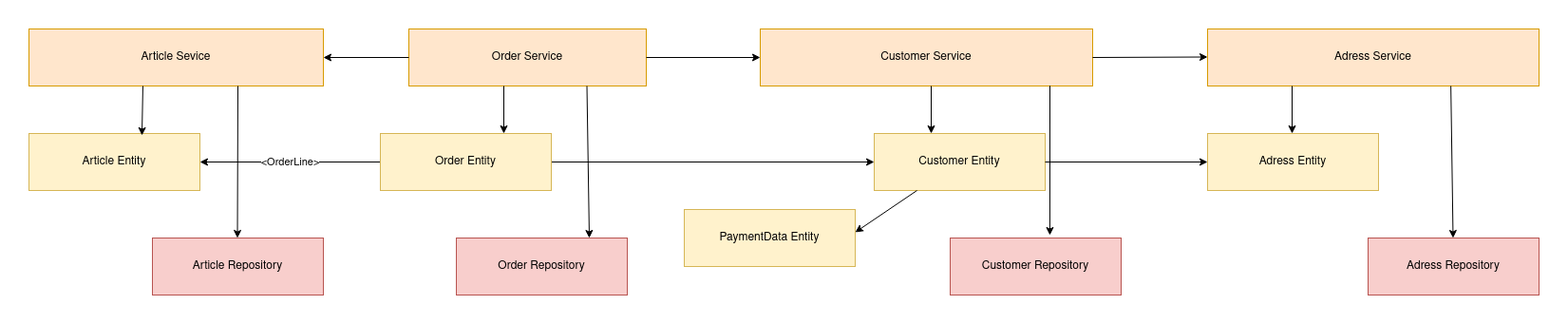
As shown in this example, there are numerous references between services and entities. Even when considering design aspects like avoiding cyclomatic references, finding a clear domain architecture remains challenging. If we consider article, order, customer, and address as domain modules, they are not well encapsulated.
In a more domain-driven approach, it may look like the following example:

There are three aggregates: ArticleAggregate, OrderAggregate, and CustomerAggregate. Each aggregate contains both data and behavior and is treated as a unit of work, meaning its entities are persisted together.
The OrderAggregate contains an OrderLineEntity. It is crucial that the aggregates share nothing with each other. This principle also influences database design. For instance, the CustomerAggregate includes payment data and address data. While one solution could involve treating them in third normal form – allowing one address to be referenced by many customers – in this example, the address is part of the customer aggregate. If two customers share the same address, the address information would be duplicated in each customer’s aggregate.
Conclusion and Future Outlook for Domain-Driven Design (DDD)
This approach provides the benefit of a clear business architecture with well-defined modules. Each module encapsulates its own data and behavior, allowing changes to one aggregate without causing side effects to others.
Another advantage arises when a (micro)service grows too large; it becomes easy to divide it into multiple services, meaning one bounded context can split into different bounded contexts. This process is straightforward because the aggregates should not depend on one another. This strategy is also an effective tactic for refactoring larger monoliths.
However, as with everything in software engineering, this approach has its disadvantages. One significant drawback is that with less encapsulation, it is possible to make individual database joins between entities and query them together. This is often useful when there is a need for creating larger view models that contain data from across a substantial part of the domain. In contrast, the Domain-Driven Design approach does not allow such joins at the database level since the aggregates should remain uncoupled. With modern architectures, you can load multiple aggregates in parallel and join them into a view model in memory. For these problems, further design patterns like Command Query Responsibility Segregation (CQRS) can also be beneficial when needed.